Converting PDF into images using python on AWS Lambda.

Let me guess why you’re here.
Probably you are working on your amazing project and you need to write a server-less function to convert PDF files into images. But things are not going in the right direction.
Don’t worry, this article will help you.
This article is divided into two parts, in the first part, we will learn how to convert pdf files into images using the pdf2image library in python. In the second part, we will learn how to deploy pdf2image and its dependencies perfectly on AWS Lambda.
The First Part…
Pdf2image is the most popular library for converting PDFs into images. It has more than 860 stars on Github. It is a wrapper around pdftoppm and pdftocairo. These two libraries come with the poppler_utils package.
poppler_utils comes preinstalled on major Linux Operating Systems. If you’re using Linux like me, you are good to go. If you’re using Windows or Mac, then I’d suggest you go to the documentation and install poppler_utils on your system.
After you’ve installed poppler, open your terminal and run the following command to make a directory for our code. You can name it whatever you would like, I am keeping it pdf2image-lambda
mkdir pdf2image-lambda && cd pdf2image-lambdaWe will create a virtual environment with python. You can learn more about virtual environments here
python -m venv envactivate the virtual env
source env/bin/activateOur virtual environment is ready, now we can install pdf2image using pip.
pip3 install pdf2imageCreate a new file app.py and write the following code in it.
from pdf2image import convert_from_bytesdef main():
f = open("resume.pdf", "rb")
infile = f.read()
f.close() images = convert_from_bytes(infile) for idx, img in enumerate(images):
img.save(f"{idx}.jpg", "jpeg")if __name__ == "__main__":
main()
We are importing the convert_from_bytes function from pdf2image. First, we read the file into the memory and then pass it to the convert_from_bytes function. It gives us the list of PIL image objects representing each page of the pdf. After it, we iterate over the images list and save them one by one.
You can see the script in action below. Here I am converting my resume into images.
The second part…
We will follow a real-world approach. We will develop an AWS Lambda function that will read PDF files from an S3 bucket, convert it into images, and save the images to an S3 bucket.
To work with AWS Lambda easily, we will use the Chalice framework. It is the official framework by AWS to develop serverless functions in python. I’d suggest you follow the quick start guide of Chalice before moving on to the next part.
When you’re ready, enter the project directory and install the chalice and boto3 SDK. Make sure to activate the virtual environment before installing.
pip3 install chalice
pip3 install boto3Create a new project with Chalice
chalice new-project _lambda
cd _lambdayou will notice that in the _lambda directory, we have an app.py and requirements.txt file already created for us. Add boto3 and pdf2image in the requirements.txt file.
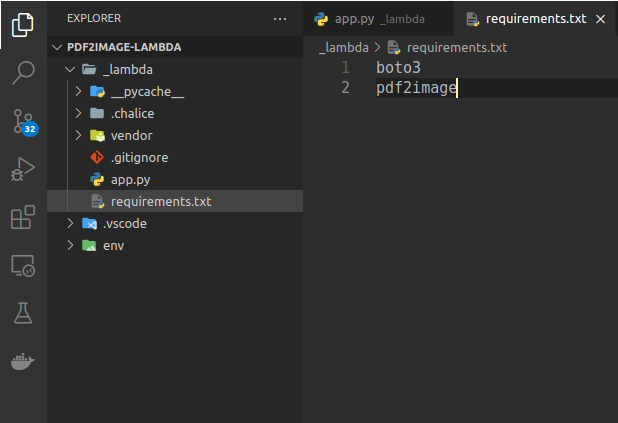
Here comes the part that you were waiting for. We will learn how to successfully build the dependencies of pdf2image for AWS Lambda. We will use Docker for this purpose. You can install Docker from here.
Create a new directory anywhere on your computer. In this directory, create two files
- Dockerfile
- build-poppler.sh
Populate the Dockerfile with the following code.
FROM ubuntu:18.04# Installing dependenciesRUN apt update
RUN apt-get update
RUN apt-get install -y locate \
libopenjp2-7 \
poppler-utilsRUN rm -rf /poppler_binaries; mkdir /poppler_binaries;
RUN updatedb
RUN cp $(locate libpoppler.so) /poppler_binaries/.
RUN cp $(which pdftoppm) /poppler_binaries/.
RUN cp $(which pdfinfo) /poppler_binaries/.
RUN cp $(which pdftocairo) /poppler_binaries/.
RUN cp $(locate libjpeg.so.8 ) /poppler_binaries/.
RUN cp $(locate libopenjp2.so.7 ) /poppler_binaries/.
RUN cp $(locate libpng16.so.16 ) /poppler_binaries/.
RUN cp $(locate libz.so.1 ) /poppler_binaries/.
RUN cp $(locate libfreetype.so.6 ) /poppler_binaries/.
RUN cp $(locate libfontconfig.so.1 ) /poppler_binaries/.
RUN cp $(locate libnss3.so ) /poppler_binaries/.
RUN cp $(locate libsmime3.so ) /poppler_binaries/.
RUN cp $(locate liblcms2.so.2 ) /poppler_binaries/.
RUN cp $(locate libtiff.so.5 ) /poppler_binaries/.
RUN cp $(locate libexpat.so.1 ) /poppler_binaries/.
RUN cp $(locate libjbig.so.0 ) /poppler_binaries/.
RUN cp $(locate libfreetype.so.6) /poppler_binaries/.
Here we are creating a Dockerfile that will run Ubuntu in a Docker container and will install all the libraries that we need. After installing, we will copy all the required libraries to a specific folder — /poppler_binaries.
Now we need to build an image from this Dockerfile. We will run a Docker container based on this image and copy the libraries from the Docker container to our host system.
We will automate this task by writing a script. (because we are programmers 😄) Write the following code in build-poppler.sh that we created earlier.
# Make the directory that will contain the binaries on host
mkdir -p poppler_binaries# Build the image
docker build -t poppler-build .# Run the container
docker run -d --name poppler-build-cont poppler-build sleep 20# Copy the files to the host
sudo docker cp poppler-build-cont:/poppler_binaries .# Cleaning up
docker kill poppler-build-cont
docker rm poppler-build-cont
docker image rm poppler-build
To execute this script, we will use chmod to add execution permission to this file.
chmod +x ./poppler-build.shAfter this, execute the script
sudo ./poppler-build.shYou can also find these files on their Github repo. Script execution will look like this.
Sending build context to Docker daemon 4.608kB
Step 1/23 : FROM ubuntu:18.04
18.04: Pulling from library/ubuntu
284055322776: Pull complete
Digest: sha256:0fedbd5bd9fb72089c7bbca476949e10593cebed9b1fb9edf5b79dbbacddd7d6
Status: Downloaded newer image for ubuntu:18.04
---> 5a214d77f5d7
Step 2/23 : RUN apt update
---> Running in 1405fbb07558
....
....
....You will notice that a folder named poppler_binaries has been created for you. It contains all the compiler libraries that we need on AWS Lambda.
Let's deploy these libraries on AWS Lambda. We can easily include pre-compiled libraries using Chalice.
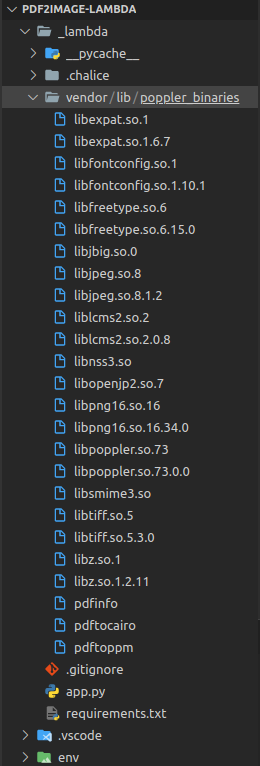
Inside your Chalice project, which is _lambda in our case. Create a folder named vendor and inside the vendor, create a subfolder named lib. Carefully copy the poppler_binaries folder inside the lib folder.
Your folder structure should look like this.
As I mentioned, we are following a real-world scenario, we will be using S3 buckets with our Lambda function to read PDF files and for saving images. We will create two S3 buckets, one for pdf files and the other for images. You can name them however you like.
Upload some pdf files to the S3 bucket that you created for PDFs.
Now we need to add an inline policy to our Lambda function that will give it access to the S3 buckets. Go to your Lambda function dashboard. Under the Configuration tab, go to permissions and under the Execution role, click on the name of your Lambda function. It will take you to the IAM Management Console page.

Under the permissions tab, you will see a button on the right side. Add inline policy. Click on it and you will be taken to Create Policy Page. Click on the JSNO tab and replace the JSON object with the following.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
}
For the sake of the tutorial, we are providing access to all the S3 Buckets to our lambda function and our function can perform any actions onto them.
Click on Review Policy, give it a nice name, and then create the policy.

Congratulations, you’ve made it so far. 🔥
We have everything ready, now it's time to write some code. Open the app.py file that Chalice created for us and write the following code in it.
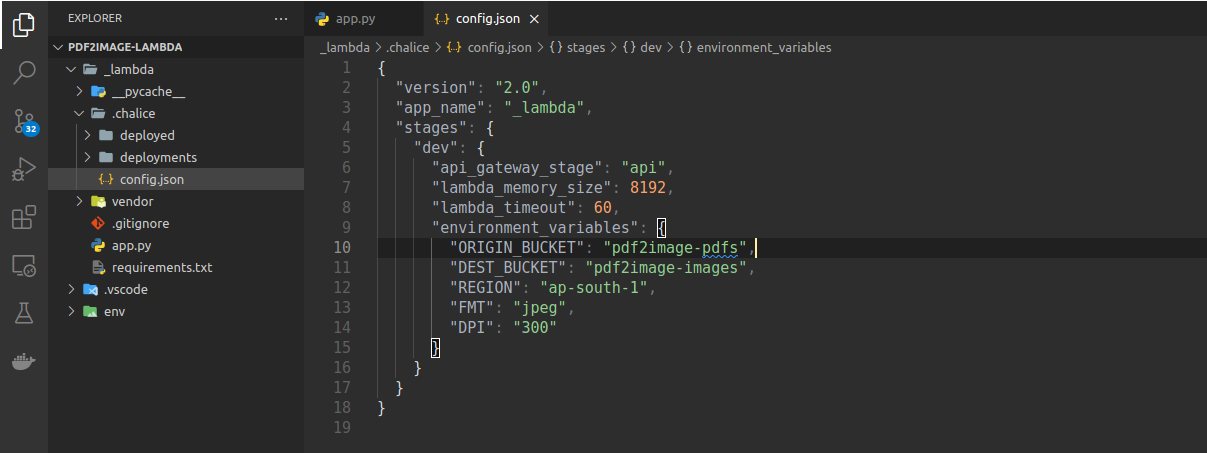
Before we deploy, let's make sure that we are passing the correct environment variables. Go to the config.json file inside the .chalice folder. Add the following environment variables inside the dev object -
"environment_variables": {
"ORIGIN_BUCKET": NAME_OF_YOUR_PDF_BUCKET,
"DEST_BUCKET": NAME_OF_YOUR_IMAGES_BUCKET,
"REGION": REGION,
"FMT": "jpeg",
"DPI": "300"
}your config.json file should look like this.
Let's Deploy 😃.
chalice deploy
Postman will help us in testing the lambda function. Make a request to the REST API URL that is generated after Chalice deploy.

You can view the logs in CloudWatch.

We have our images ready in the S3 bucket.

I hope you learned something valuable from this article. If you find any mistakes or would like to give me feedback of any kind, please share them in the comments.
